Week 9: Text Mining
Reading Response
Machine learning and text mining techniques are commonly used to detect patterns in large numbers of documents that would simply take too long for humans. This is sometimes referred to as “distant reading” – where the researcher need not necessarily have any knowledge of the content of the corpus – in contrast to “close reading” – where the researcher has an intimate knowledge of the content of the text.
Ted Underwood identified the following ways that computers can be used to analyze text:
- visualize single texts (eg, visualize plot lines or relationships among characters)
- choose features to represent texts (eg, what words are associated with an author or genre)
- identify distinctive vocabulary (eg, language differences between race and gender)
- find or organize works (ie, bibliographic metadata)
- model literary forms or genres (eg, what linguistic features distinguish poetry and prose)
- model social boundaries (eg, identify relationships among characters or places)
- unsupervised modeling (ie, let the computer figure out the patterns within the corpus, rather than train it to identify the patterns)
The key is to use the computational power of the computer to do things that a human cannot do with traditional sequential reading. Moreover, it is the role of the humanist to attempt to explain the differences elucidated by the machine’s textual analysis. A text mining exercise that reveals that the male and female characters of male and female authors speak differently and about different things (e.g., here) is not a surprising finding. The humanist must take the next step of analyzing the reasons for these outcomes.
Using Voyant
I decided to use a corpus I knew something about from an earlier project – the oral histories of the 1967 riots in Detroit collected by the Detroit Historical Society. You can learn more about the Detroit 67 Project here.
As an aside, I was rather pleased with myself for using Beautiful Soup to write a Python script to extract the transcripts from the webpages into individual text files to use in Voyant. I was pleasantly surprised I got it to work as intended.
According to Voyant, This corpus has 206 documents with 943,428 total words and 18,651 unique word forms.
I did not get much out of Voyant on the macro level, but I separately loaded the individual text file for the interview of Donald Lobsinger to see what I could get on the micro level. I chose this one because it was one of the longer interviews in my corpus so would have enough words to work with. Here’s the word cloud that Voyant produced:

I knew that Lobsinger was a high-profile anti-communist agitator at the time, and this is born out in the word cloud with prominent words like communist. You can also see individual references to martin, luther, and king, and it would make more sense to consider those a single word than three separate words. The reference to Berlin is peculiar in this context of an oral history about Detroit, and reinforces that much of the testimony referenced Communism.
The word cloud revealed some issues with stop word lists - I would need to add ww and dl, the initials of the interview participants to the stop word list so that the algorithm ignored them.
The most frequent words list detroit (90); communist (67); people (60); city (50); ww (49) indicated that I should probably add the words Detroit, people, and city too.
You can also see some interesting things in the document segments window. This shows the term frequency of the words communist and black during segments of the interview:
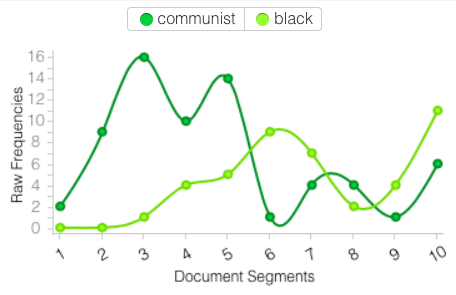
The end of the interview must have been interesting!